Analytics and this blog: recovering information without tracking
This post is the first of a monthly serie dedicated to the tools and libraries I use often and deserve (in my opinion) to be more widely known.
Today, for the first post of the serie, I want to talk about a subject that impact everyone in their daily live on the Internet: analytics.
What are analytics?
The word “Analytics” is defined by the Oxford dictionnary as
The systematic computational analysis of data or statistics.
Note: if you clicked on the Oxford link above from an IP address within the European Union, do not forget to uncheck all the non-necessary cookies or let Ninja Cookie do it for you.
I will come back to this later.
On the Internet, analytics are a set of programs used to retrieve and analyse the behaviour of users on websites. They help answering the following questions:
- How many visitors have visited my website?
- From where did they come?
- How much time did they stay?
- What pages did they read?
- …
Basically they help webmasters understanding how their audience (visitors of their website) behaves.
This understanding of visitors can then be used to improve several metrics, for example the number of pages viewed on average by one user or the number of visits that ended up with a trade.
What is the issue with analytics today?
Or rather
What are the issues with analytics today?
First and foremost, the monopoly. According to w3techs.com, on the 23rd of March 2021, Google Analytics is used by 55.1% of all the websites.
This means that at least 55.1% of all the websites are tracking you and extract data to compute the statistics they need. But the real issue here is not that one website tracks you because the personal data collected on one website is not significant enough to analyse your general behaviour. It is that one company (Google here) is able to track you on each of these websites and gather the data on you from each of these 55.1% websites.
And this makes a wonderful transition to the second issue with
Google Analytics: the statistics collected are linked to you via
a persistent unique identifier.
Whenever you are visiting a website that use Google Analytics,
Google know who you are because they left this unique identifier
in a cookie on your browser (the _ga cookie).
You may be aware of a new regulation in the European Union that apply to everyone within its frontiers: the General Data Protection Regulation. Among other things, this regulation makes all the personal data collection as opt-in: you no longer have to opt-out if you care about your privacy, websites that may collect personal informations needs to have your explicit approval to do so.
And this leads us to the last and most user-visible issue with analytics today: cookie consent pop-ups. If you used the Internet from a European IP address in the last 2 years you know what I am talking about. For non-European reading this, a screenshot of a famous french media webpage (https://www.lemonde.fr) when accessed for the first time:
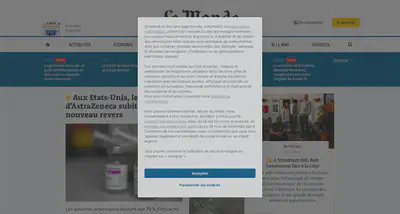
It is important to realise that this pop-up (or a similar one) is encountered on each website that want to store personally identifiable data about you, meaning that the 55.1% websites that use Google Analytics have the legal obligation to show such a pop-up. And it is not limited to Google Analytics.
Moreover, the pop-up is made such that it is easy to accept all the cookies but harder to not accept them. That is why extensions like Ninja Cookie exist.
Finally, if you end up refusing cookies, the website has no way of identifying you: this is the whole point of the procedure. But this means that you will appear as a completely new visitor the next time you go on the website, and so you will again have to refuse cookies over and over.
What about this blog?
This blog is my personal space where I write and show things about myself, my work and my hobbies. As such, I want it to adhere to my personal convictions which are oriented towards privacy and free and open-source software.
Analytics as depicted in the previous section are one of the most prominent threat to privacy today as they allow companies to have statistically significant data about the behaviour of individuals.
So my initial position was the following: this blog will never use analytics because I want to respect the visitors’ privacy and I do not want to help feed Google with my visitors’ data.
But this was my initial position and, as you may guess, it changed.
Plausible, or the analytic framework that checks all the boxes
My view on analytics scripts changed when I discovered that not all analytics framework were like Google Analytics, more precisely when I discovered Plausible.
![]()
![]()
It is basically the perfect fit for me (and you):
- It is open-source.
- It is privacy focused.
- Its documentation is very nice.
- Self-hosting is maintained by the Plausible team.
- Everything is just simple, open, and works.
With my knowledge of web technologies in general (which is nearly inexistant) and my kind of basic understanding of Docker, I just installed and setup Plausible on my website in less than an hour, from scratch.
If you are not convinced yet, just know that along with the documentation and the public roadmap, the Plausible team (in fact one of the 2 people composing the team) is also maintaining a blog that includes very interesting posts.
All in all, Plausible has been a real pleasure to setup and to use. It is running on this blog since the end of February and allowed me to learn a lot about my audience (you) and the most read posts, by still preserving yout privacy. In order to be as transparent as possible, you can have access to the Plausible dashboard here: https://plausible.suau.me/adrien.suau.me. The data you see is updated in real time and is the only thing that is stored.
Adrien Suau
Senior Open-Source Software Engineer
Open-source advocate working on the quantum error-correction software stack.